사실 앞서 설명했던 한글 코드들과, 여기서 설명할 이야기들.. 웬만한 분들은 아직도 무슨 이야기인지 감이 잡히지 않을 지도
모르겠다,
사실 몰라도 커다란 지장은 없다.
마치 세벌식의 존재를 몰라도 두벌식으로도 뭐가 불편한지 모르고 타이핑하듯이 말이다.
그런데 그러한 일반 유저들도, 간혹 이러한 경험을 한번쯤은 했을 것이다.
상황1>
“사진을 인터넷 게시판에 업로드 했는데 사진이 보이질 않아요 왜그렇죠?”
“혹시 파일 이름이 한글로 되어있나요?”
“네 그런데요?”
“가능하면 파일 이름에 한글이 들어가지 않도록 해주시고요.
한글로 된 파일을 보시려면 웹브라우저에서 도구-인터넷옵션-고급 메뉴로 들어가셔서요.
'URL을 항상 UTF-8로 보냄.' 이라고 쓰여있는 옵션을 끄세요.”
“왜 이렇게 복잡하죠?”
상황2>
“메일을 하나 받았는데 글씨를 전혀 알아볼 수 없어요. 외국에서 보낸건가요?”
“그 메일을 보시려면 인코딩을 ······.”
왜 한글로 된 파일 하나 인터넷으로 다운 받으려는데 평소 전혀 들어가 볼 일도 없는 '고급'메뉴까지 들어가야 할 정도로
복잡하고 어려운 것인가? 같은 한글로 된 이메일인데 왜 인코딩 변환까지 해가면서 봐야 한글을 읽을 수 있는 것인가?
그것은, 인터넷에서 사용하고 있는 한글 코드가 현재 알려진 2~3개가 모두 쓰여지고 있기 때문이다.
다행히 최근에 제작되는 인터넷 자료실이나 게시판, 이메일등은 이러한 것을 몰라도 알아서 처리해주니 큰 걱정은 하지
않아도 된다.
이러한 복잡한 상황은 고스란히 웹 프로그래머의 몫으로 돌아가는 것이고 이를 제대로 알아야만 중급 프로그래머로서 자리를
잡게 될 것이다.
현재 인터넷에서 사용되는 한글 코드는 크게 세가지가 존재한다.
※ KS 완성형 한글(KSC5601, EUC-KR)
역시 2350개의 글자밖에 쓸 수 없는 코드이다.
다음 블로그 등에서 이 코드가 쓰이는데, 이때 표준을 벗어난 한글은 아래에서 설명할 UNICODE로 강제변환시키는 코드를
사용하게 된다.
'똠방각하'라고 저장을 하고자 할때 서버의 데이터 값은 UNICODE 호출을 위해 '똠방각하'라고 변환되어 저장된다.
※ MS 확장 완성형 한글(MS949, CP949)
바로 앞장에서 설명한, 어느 표준에도 포함되지 않은 MS 전용한글 코드이나, 통합 한글코드라는 이름으로 거의
표준화되다시피 하여 JAVA등에서 제공된다.
일부 MS이외의 OS에선 이 코드로 작성된 문서를 보지 못할 수도 있다.
(※ 2007/12/3 내용 정정합니다. JAVA에서는 내부적으로는 UNICODE의 케릭터 셋이 사용됩니다. 다만 입출력을 UNICODE로 하기 위해서는 UNICODE, 혹은 UTF에 관련된 입출력 메소드를 이용하여야 합니다.)
※ UNICODE (UTF-7, UTF-8, UTF-16)
엄밀히 말하면 유니코드와 UTF의 개념은 틀리지만 UTF란 UNICODE를 표기하기 위한 방법이므로 함께 설명하겠다.
먼저 유니코드는 국제 표준화 기구는 아니며 컴퓨터 관련 업계를 중심으로, 다국어 언어를 효율적으로 처리에 필요한 코드
체계를 제정하기 위해서 1989년에 콘소시엄 형태로 설립된 회사이다.
1991년 말, 유니코드 1.0을 제정하였는데, 이때 한글 코드는 KSC5601-1987만을 포함시켰다.
이후 제정된 유니코드 1.1에서는 조합형한글을 부분적으로만 수용하여 발표하였으나 이는 사용조차 할 수 없는 형태로
이루어졌다.
1995년이 되어서야 유니코드 2.0이 제정되었다.
이 유니코드는 한 글자가 차지하는 용량을 2바이트를 기본으로 하며, 한중일 통합 한자 확장 등의 몇몇영역은 2바이트가 넘는
코드값이 쓰이기도 한다.
기존 7비트 ASCII영역 또한 전체적인 호환을 위해서 2바이트 영역에 배치되었다.
즉, 대문자 알파벳은 0041~005A에, 소문자 알파벳은 0061~007A에 배치되는 등 2바이트를 기본 구조로 사용한다.
2바이트를 넘는 문자를 제외하고 2바이트 문자만 고려한다면 유니코드는 약 6만 개의 글자를 표현할 수 있는데,
이중 한글을 위해서 만 개가 넘는 코드를 배정받은 것은 고무적인 일이다.
유니코드 2.0에서는 11172자의 완성형 한글코드를 담을 수 있는 영역(AC00~D7AF)과 조합형에 사용할 수 있는 초성, 중성,
종성의 옛한글을 포함한 한글 자모 영역(1100~11FF), 그리고 기존 완성형과의 호환성을 위한 한글 자모 영역(3130~318F)등을
한글을 위해 배정받았다.
이 유니코드는 발표되자마자 국내표준으로도 채택되었으며, KSC5700이라는 이름으로 제정되어있다.
유니코드의 완성형 한글은 지금까지 나온 완성형 한글 중 가장 이상적이다.
11172자의 현대한글에서 조합가능한 모든 글자가 사전 순서대로 나열되어있다.
이 말은 즉 완성형과 조합형간의 변환이 별도의 변환테이블이 없이 코드값의 수식 계산만으로도 가능하다는 이야기다.
유니코드 완성형 한글의 계산방법은,
우선 한글 자모의 인덱스를 다음과 같이 둔다.
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
|
초 |
ㄱ |
ㄲ |
ㄴ |
ㄷ |
ㄸ |
ㄹ |
ㅁ |
ㅂ |
ㅃ |
ㅅ |
ㅆ |
ㅇ |
ㅈ |
ㅉ |
ㅊ |
ㅋ |
ㅌ |
ㅍ |
ㅎ |
|
|
|
|
|
|
|
|
|
|
중 |
ㅏ |
ㅐ |
ㅑ |
ㅒ |
ㅓ |
ㅔ |
ㅕ |
ㅖ |
ㅗ |
ㅘ |
ㅙ |
ㅚ |
ㅛ |
ㅜ |
ㅝ |
ㅞ |
ㅟ |
ㅠ |
ㅡ |
ㅢ |
ㅣ |
|
|
|
|
|
|
|
|
종 |
X |
ㄱ |
ㄲ |
ㄳ |
ㄴ |
ㄵ |
ㄶ |
ㄷ |
ㄹ |
ㄺ |
ㄻ |
ㄼ |
ㄽ |
ㄾ |
ㄿ |
ㅀ |
ㅁ |
ㅂ |
ㅄ |
ㅅ |
ㅆ |
ㅇ |
ㅈ |
ㅊ |
ㅋ |
ㅌ |
ㅍ |
ㅎ |
그러면 조합된 완성형 한글의 코드값에 대한 공식이 바로 나온다.
(유니코드 완성형 한글코드) = 0xAC00 + 28*21*(초성인덱스) + 28*(중성인덱스) + (종성인덱스)
예를 들어, '한'이라는 글자의 코드값은
0xAC00 + 28*21*(18) + 28*(0) + (4) = 0xD55C
가 된다.
반대로, 완성된 코드값을 조합형으로 분해하는 것도 간단하다.
(int(A) : A의 소숫점 이하를 버린 값, 정수)
(mod(A,B) : A를 B로 나눈 나머지)
(초성인덱스) = int(((유니코드)-0xAC00) / 28*21)
(중성인덱스) = int(mod((유니코드)-0xAC00, 28*21) / 28)
(종성인덱스) = mod((유니코드)-0xAC00, 28)
예를 들어, '특'이라는 글자의 유니코드 값은 0xD2B9 이며, 이를 계산하면
0xD2B9-0xAC00 = 0x26B9 → 9913
28*21 = 588
(초성인덱스) = int(9913 / 588) = 16 (ㅌ)
mod(9913, 588) = 505
(중성인덱스) = int(505 / 28) = 18 (ㅡ)
(종성인덱스) = mod(9913, 28) = 1 (ㄱ)
이 됨을 알 수 있다.
이렇듯 유니코드는 완성형 한글임에도 불구하고 KS 완성형처럼 빠진글자도 없으며, MS 완성형처럼 순서가 뒤죽박죽이
아닌 덕분에, 마치 조합형처럼 간단한 수식으로 한글 자모를 분해, 조합할 수 있는 것이다.
사전적인 배열이므로, 검색이나 정렬 등에서 처리가 훨씬 쉬워졌음은 물론이다.
그런데, 위에서 언급한 대로, 유니코드에서는 조합형을 위한 영역을 따로 두었다고 하였다.
유니코드 조합형을 위한 한글자모들.
초성 :
ᄀᄁᄂᄃᄄᄅᄆᄇᄈᄉᄊᄋᄌᄍᄎᄏᄐᄑᄒᄓᄔᄕᄖᄗᄘᄙᄚᄛᄜᄝᄞᄟᄠᄡᄢᄣᄤᄥᄦᄧᄨᄩᄪᄫᄬᄭᄮᄯᄰᄱᄲᄳᄴᄵᄶᄷᄸᄹᄺᄻᄼᄽᄾᄿᅀᅁᅂᅃᅄᅅᅆᅇᅈᅉᅊᅋᅌᅍᅎᅏᅐᅑᅒᅓᅔᅕᅖᅗᅘᅙ
중성 :
ᅡᅢᅣᅤᅥᅦᅧᅨᅩᅪᅫᅬᅭᅮᅯᅰᅱᅲᅳᅴᅵᅶᅷᅸᅹᅺᅻᅼᅽᅾᅿᆀᆁᆂᆃᆄᆅᆆᆇᆈᆉᆊᆋᆌᆍᆎᆏᆐᆑᆒᆓᆔᆕᆖᆗᆘᆙᆚᆛᆜᆝᆞᆟᆠᆡᆢ
종성 :
ᆨᆩᆪᆫᆬᆭᆮᆯᆰᆱᆲᆳᆴᆵᆶᆷᆸᆹᆺᆻᆼᆽᆾᆿᇀᇁᇂᇃᇄᇅᇆᇇᇈᇉᇊᇋᇌᇍᇎᇏᇐᇑᇒᇓᇔᇕᇖᇗᇘᇙᇚᇛᇜᇝᇞᇟᇠᇡᇢᇣᇤᇥᇦᇧᇨᇩᇪᇫᇬᇭᇮᇯᇰᇱᇲᇳᇴᇵᇶᇷᇸᇹ
비어있는 코드를 제외하면 위의 자모들은 유니코드에서 0x1100~0x11FF안에 위의 순서대로, 초성 90자, 중성 66자,
종성 82자와, 중성 채움, 종성 채움의 모두 240자가 배치가 되어있다.
말 그대로 조합형 코드이기때문에, 초성+중성+종성을 합한 유니코드 세글자는 완성된 한글자로 인식될 수 있다.
예를 들어 'ㄱ(0x1100)' + 'ㅏ(0x1161)' + 'ㄱ(0x11A8)' 은 '각(0xAC01)'이란 글자와 같이 인식될 수 있다. 실제로, 유니코드
한글의 재정 원칙상, 위의 조합형 코드와 완성형 코드는 동일한 글자로 처리해야 한다.
헌데, 여기에는 중요한 문제가 몇가지 있다.
첫째는 유니코드 한글조합형을 지원하는 시스템이 OS차원에서는 아예 없으며, 응용 프로그램에서도 거의 전무하다는 것이다.
0x1100116111A8 = 0xAC01 이어야 하는데 실제 이 조합형을 입력했을 경우 대부분 'ㄱㅏㄱ'이라고만 찍혀나오지 '각'이라고
출력되어 나오는 소프트웨어가 거의 없다는 것이다.
지금까지 본인이 확인해본 바로는 김용묵님의 『날개셋 편집기』가 유일하게 유니코드 조합형 한글을 사용하고 있다.
현재 유니코드를 지원하는 대부분의 프로그램에서는 한글을 오직 완성형으로만 인식하며, 한글자모 단독출력도 기존 완성형과의
호환을 위해서 호환용 자모 영역(3130~318F)을 이용하고 있다.
(※ 2007/12/22 내용 정정합니다. 직접 확인해 보지는 못했지만 MS-Windows Vista 버전에서는 유니코드의 한글 조합형을 지원한다고 합니다.)
둘째는 옛한글 지원의 문제이다.
유니코드에는 완성형 한글이 오로지 현대 한글로만 이루어져있으며, 옛한글을 사용하기 위해서는 조합형을 사용해야 한다.
사실 위의 옛한글 자모로 조합가능한 모든 글자가 무려 50만 자 가까이 되니 이를 완성형으로 표현한다는 것이 사실상
불가능하기도 하다. 그러나 금방 언급했듯이, 이 조합형을 지원하는 소프트웨어가 거의 없으며, 한글자모 자체가 현대한글과
옛한글로 나뉘어져 사전순서가 맞지 않는다는 문제도 있다.
위의 옛초성 중에서 ᄜ과 ᄝ은 ㅁ과 ㅂ사이에 들어와야 순서가 맞지 않겠는가.
또한 옛한글의 자모가 위의 240개가 전부가 아니며, 104자가 추가된 344자가 있어야 현재 알려진 모든 옛한글을 표현할 수
있다고 한다.
그러나 255자로 제한된 유니코드 조합형의 한글자모 영역에 이 104자를 추가할 수 있는 방법이 없다.
이는 유니코드를 준비하던 사람들의 사전 준비가 부족한 탓이라고 하니, 한글 코드표준화의 역사를 보면 한숨만 나올 뿐이다.
셋째로, 조합 방법의 문제이다.
조합 방법에 대한 구체적인 표준이 불분명하다.
어느 문헌에서는 첫가끝 고정바이트 방식을 사용한다고 명시 되어 있으나 또 어느 문헌에서는 이에 대한 언급이 없다.
채움 코드가 있는 것으로 봐서는 첫가끝 고정바이트 방식을 사용하는 것이 맞겠지만, 초성에 대한 채움 코드도 불명확하다.
공식 문서에서는 0x115F가 초성 채움코드라는 것을 확인했는데, 김용묵님의 날개셋에서는 0x10FF를 초성채움코드로 활용하고
있다. 아래아 한글에서 유니코드표를 확인해보면 알겠지만, 이는 그루지야어(Georgian) 라는 문자 영역이며, 이는
국제 공식적으로 쓰일 경우 문제가 있을 수 있다.
그런데 사실 채움코드가 제일 첫 초성인 'ㄱ(0x1100)'의 앞으로 오게끔 하는게 정답일 것이며, 이런 면에서는 김용묵님의 선택이
맞을 수 있다. 그러면 이것 또한 'ㄱ'앞을 비워놓지 않은, 유니코드를 준비하던 사람들을 탓해야 할 것 같다.
마지막으로, 미완성 한글의 처리이다.
미완성 한글이란, 한 글자에서 초성이나 중성이 빠졌거나, 한글 자모 단독으로 쓰이는 경우인데, 특히 종성자음만 쓰일 경우
받침임을 확실히 알 수 있도록 자음이 약간 아래쪽으로 표시되게끔 하는 것이다. 현재 이러한 표기방법은 아래아한글과,
날개셋 편집기에서만 지원한다.
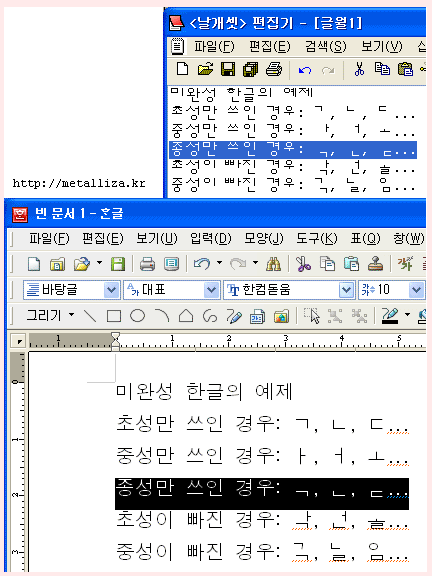
이는 조합형 지원과, 조합 방법 문제, 그리고 완성형 한글영역의 복합적인 문제가 될 수 있다.
소프트웨어가 유니코드 조합형을 지원하고, 조합 방법에서 채움코드등이 정확히 표준화 된다면 이를 표현하는데 문제가 되지
않겠지만, 현재로서는 역시 특정 프로그램에서만 쓸 수 있는 방법이다.
또 이를 표기하기 위해서 완성형은 11172자가 아니라, 이들 미완성 조합을 포함한 12319자가 되어야 한다는 이야기도 있다.
UTF 란 Unicode Transformation Format의 약자로서, 말 그대로 유니코드를 저장하거나, 보내고 받기위한 방법을
의미한다.
UTF-7, UTF-8, UTF-16등이 있으며 각각 알고리즘이 틀리다. 뒤의 숫자는 코드 처리를 위한 bit수를 의미한다.
UTF-7은 이메일 시스템에 많이 쓰이는 코드이며, 최근에는 사용량이 줄어드는 추세이다.
현재 가장 많이 쓰이고 있는 것은 UTF-8인데, 그 이유는 7bit 표준 ASCII와 완벽하게 호환이 되기 때문이다.
즉, 2바이트가 기본이 되는 유니코드를 ASCII로만 이루어진 문서에 적용하게 되면 용량이 모조리 두배가 되기 때문에,
이를 위해 고안된 것이 UTF-8이다.
UTF-8은 가변길이 방식으로, ASCII등의 문자를 표현할 때는 큰 효과를 보지만, 동양권의 문자등을 표현할 때는 많은 용량을
차지할 수 있다. 완성형 한글 영역은 3바이트를 차지하게 된다.
UTF-16은 유니코드를 2바이트가 기본이 되는 유니코드는 그대로 저장하면서, 2바이트가 넘는 코드는 4바이트로 확장하여
저장하는 방식이다.
| 코드 범위 (십육진법) |
UTF-16BE 표현 |
UTF-8 표현 |
설명 |
| 000000-00007F | 00000000 0xxxxxxx |
0xxxxxxx |
ASCII와 동일한 범위 |
| 000080-0007FF | 00000xxx xxxxxxxx | 110xxxxx 10xxxxxx | 첫 바이트는 110 또는 1110으로 시작하고, 나머지 바이트들은 10으로 시작함 |
| 000800-00FFFF | xxxxxxxx xxxxxxxx | 1110xxxx 10xxxxxx 10xxxxxx | |
|
010000-10FFFF |
110110yy yyxxxxxx 110111xx xxxxxxxx | 11110zzz 10zzxxxx 10xxxxxx 10xxxxxx | UTF-16 서로게이트 쌍 영역 (yyyy = zzzzz - 1). UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일하다. |
처음에 언급한, 파일이름이 한글로 된 자료를을 볼 때 'URL을 항상 UTF-8로 보냄.'을 해제해야 하는 이유는 이때 표현된
한글을 유니코드로 변환시키기 때문에 KS완성형으로 되어있는 본래의 파일 이름과 매치가 되지 않기 때문이다.
요즘엔 이러한 점 때문에 업로드 파일을 저장할 때 파일이름을 utf-8로 변환하여 저장하는 서버가 점점 늘고 있는 추세이므로,
사용자들은 점점 신경을 쓸 필요가 없어지고 있다.
유니코드는 현재 5.0 버전까지 발표가 되었으며, 전세계의 모든 문자를 표현할 수 있기 때문에 점차 세계 표준으로 자리를
잡아가고 있다.(ISO10646) 또한, 기존 KS완성형이 갖고 있던 약점이 많이 개선 되었기 때문에, 한글을 처리를 위해서도 좋은
선택이 되고 있다. MS에서도 Window 98버전부터 유니코드를 내장하여 왔으며, 점차적으로 유니코드의 사용량을 늘려나가고
있다.
다만, 아직까지도 KS 완성형이 쓰이고 있는 이유인 기존 데이터와의 호환성, 그리고 유니코드 조합형 한글 표현의 OS차원에서의
지원 등, 앞으로도 넘어야 할 과제들이 많다
[출처] 컴퓨터 한글 코드 - 4. 유니코드와 인터넷 한글|작성자 메탈리쟈
'Computing..' 카테고리의 다른 글
| 유니코드와 한글2 (0) | 2008.11.26 |
|---|---|
| 윈도우 레지스트리 정리 (0) | 2008.10.30 |
| Registry 에 관하여 (0) | 2008.10.17 |


